Breaking the Text Barrier: How Nano Banana Pro Actually Generates Accurate Images
Reverse-engineering why Google's Nano Banana Pro can render perfect text when DALL-E, Midjourney, and Stable Diffusion can't—and the architectural tradeoffs that make it possible. A technical deep-dive into autoregressive generation, specialized tokenization, and mixture-of-experts architecture.
Tech Stack:

Nano Banana Pro - The Precision Revolution
The Problem Everyone Ignored
For three years, AI image generators had an embarrassing secret: they couldn't spell.
Ask DALL-E to create a storefront sign, and you'd get something that looked like "COFFÉE SHØP" with backwards letters. Request Midjourney to design a product label, and the text would melt into decorative gibberish. Need Stable Diffusion to generate an infographic with data? Good luck reading those numbers.1 2 3

The Text Rendering Challenge in AI Image Generation
This wasn't a minor bug—it was a fundamental limitation that prevented AI image generation from being anything more than a creative toy. Product designers couldn't use it for mockups. Marketing teams couldn't generate social media graphics. Technical writers couldn't create diagrams. The moment you needed actual words in an image, you were back to Photoshop.4
Then in November 2025, Google released Nano Banana Pro (technically called Gemini 3 Pro Image), and something changed. The model could write. Not just simple words, but entire paragraphs, in multiple languages, with correct spelling and typography. But the more interesting question isn't that it works—it's why it works when everything else failed.6
Why AI Models Struggle With Text (The Technical Reality)
To understand Nano Banana Pro's breakthrough, you need to understand why text rendering has been so impossibly hard for AI image generators.
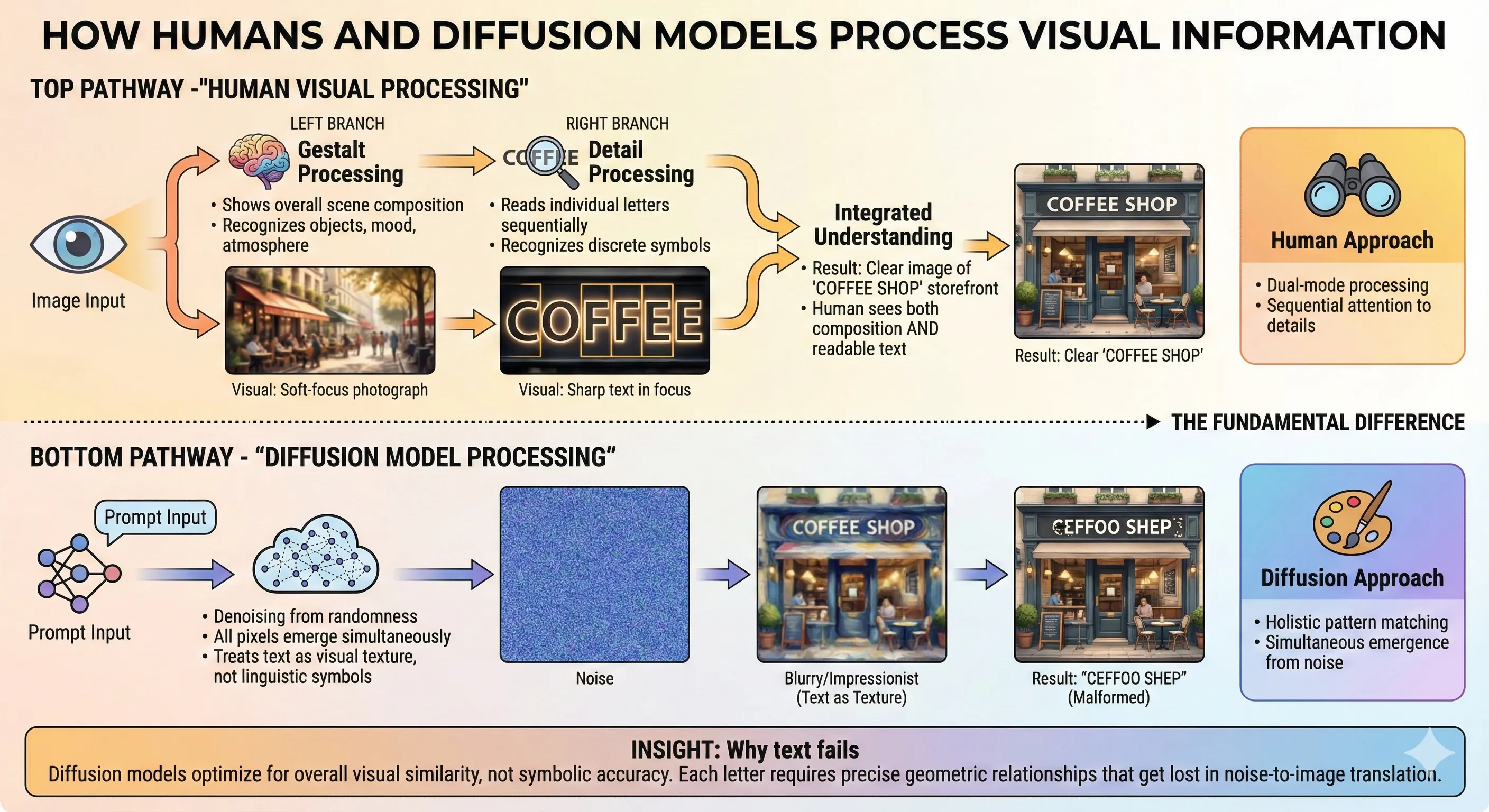
How Humans and Diffusion Models Process Visual Information
The Diffusion Problem
Most current image generators—including DALL-E 3, Midjourney, and Stable Diffusion—use something called diffusion models. Here's how they work:7
Imagine trying to recreate a photograph by starting with television static, then gradually reducing the noise while guessing what might be underneath. You'd notice broad shapes first—"there's probably a person here, a building there"—and details would emerge slowly.
This approach, called "denoising diffusion," excels at creating visually cohesive images because it considers the entire picture holistically. But it's terrible at precision tasks like writing text. Why? Because diffusion models don't understand that the letter "R" is fundamentally different from a slightly rotated "P". To them, both are just similar patterns of pixels. They're painting impressions, not drafting technical drawings.
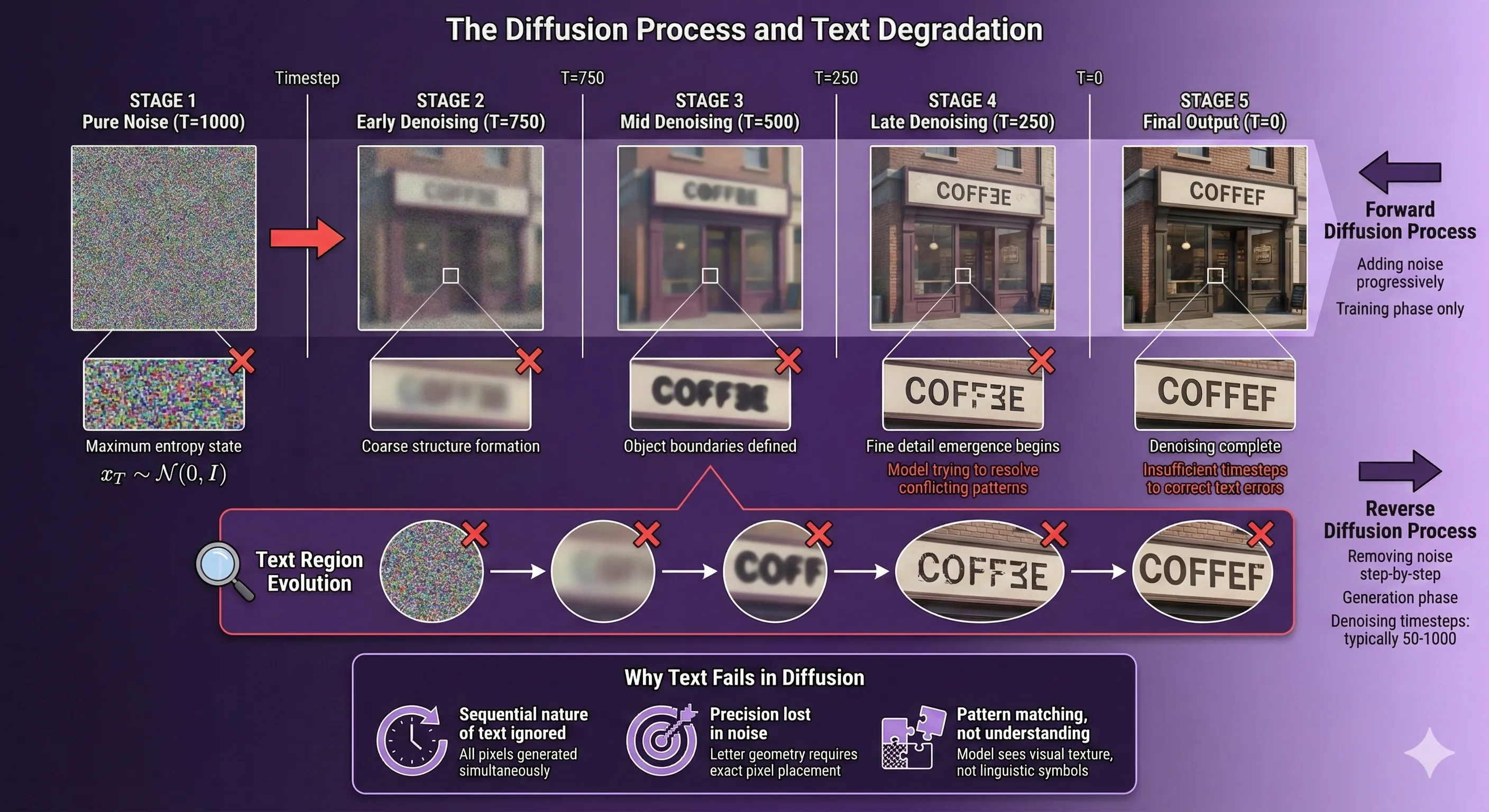
The Diffusion Process and Text Degradation
The Tokenization Gap
There's a deeper problem: how these models represent images internally.
Think of it like trying to describe a painting using only 1,000 predefined color swatches. You might get close to the original colors, but you'll lose subtle gradations. Image generation models face a similar constraint—they convert continuous pixel data into discrete "tokens" (chunks of information), process those tokens, then convert back to pixels.
This tokenization process works fine for organic shapes like faces, clouds, or landscapes. But text is unforgiving. The difference between a readable "E" and a backwards "Ǝ" might be just a few pixels—information that gets lost when you compress an image into tokens and reconstruct it.
A 2025 research paper identified this as the core issue: "Image tokenizers are crucial factors affecting the quality of text generation". Standard tokenizers simply weren't designed to preserve the fine-grained details that make text legible.
Nano Banana Pro's Three-Part Solution
So how did Google solve what seemed like an unsolvable problem? Not with one breakthrough, but with three converging technical decisions.
1. Autoregressive Architecture (Writing Letter by Letter)
Unlike diffusion models that create images holistically, Nano Banana Pro appears to use an autoregressive approach —at least for text-heavy elements.
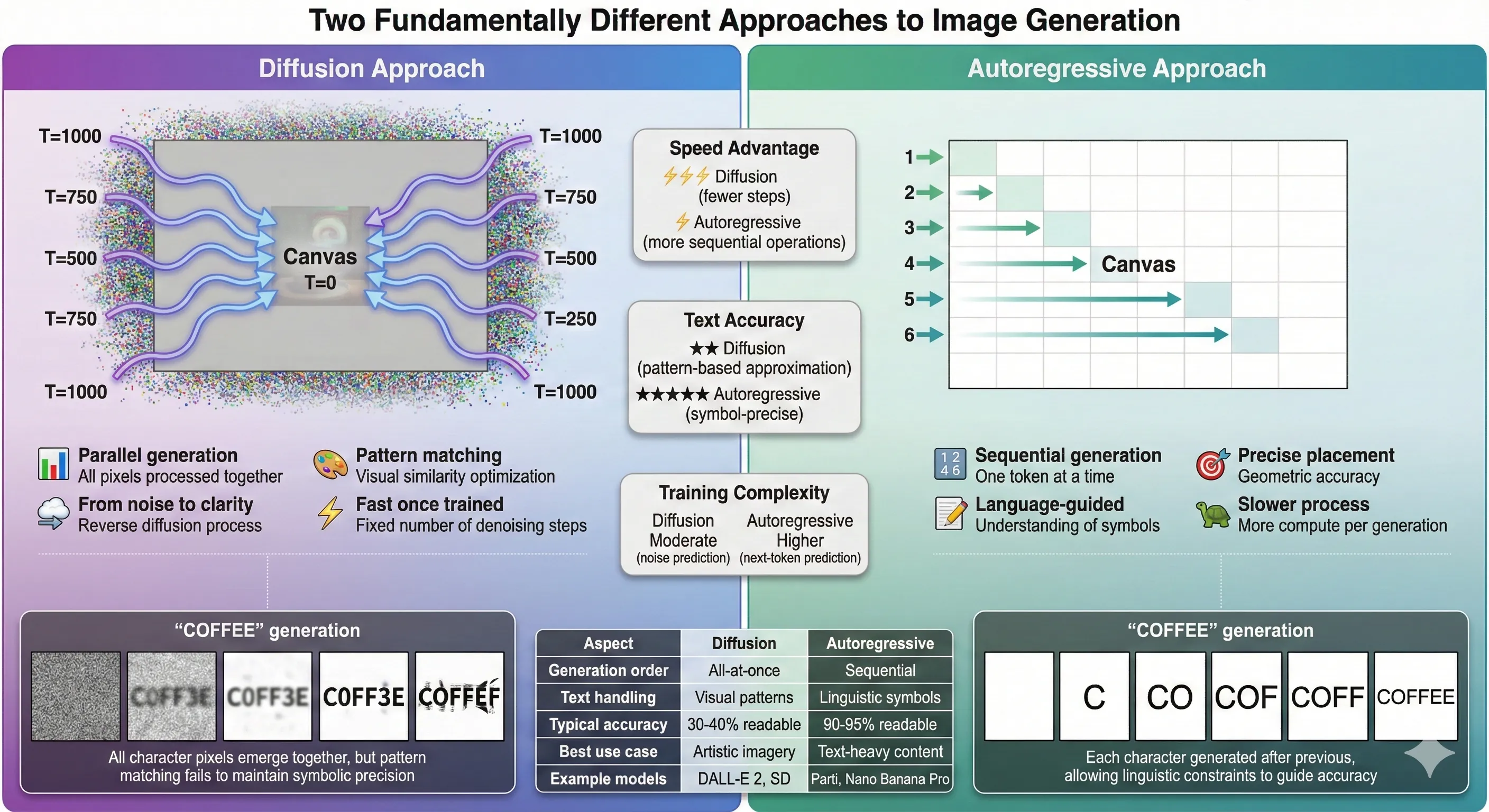
Two Fundamentally Different Approaches to Image Generation
Think of it like the difference between a photograph developing in a chemical bath (diffusion) versus a printer laying down ink line by line (autoregressive). When you print text, each letter gets rendered precisely, one after another, with clear boundaries and exact positioning.
Autoregressive models generate content sequentially, predicting each next piece based on what came before. For text, this means: "I've written 'CO', so the next token should be 'F', then another 'F', then 'E', then 'E'". The model understands the discrete nature of language because it's fundamentally built from language models.9
Research shows autoregressive models "give you a much better chance of drawing letters correctly" compared to diffusion's gestalt approach. They're slower—generating sequentially takes more steps than parallel processing—but the precision is worth it.
2. Specialized Binary Tokenizer for Text
Google appears to have implemented a specialized tokenizer specifically optimized for text rendering.
Standard image tokenizers try to compress all visual information equally—treating text the same as trees, clouds, or faces. But text has unique properties: hard edges, specific geometric relationships between strokes, and cultural expectations about letterforms.
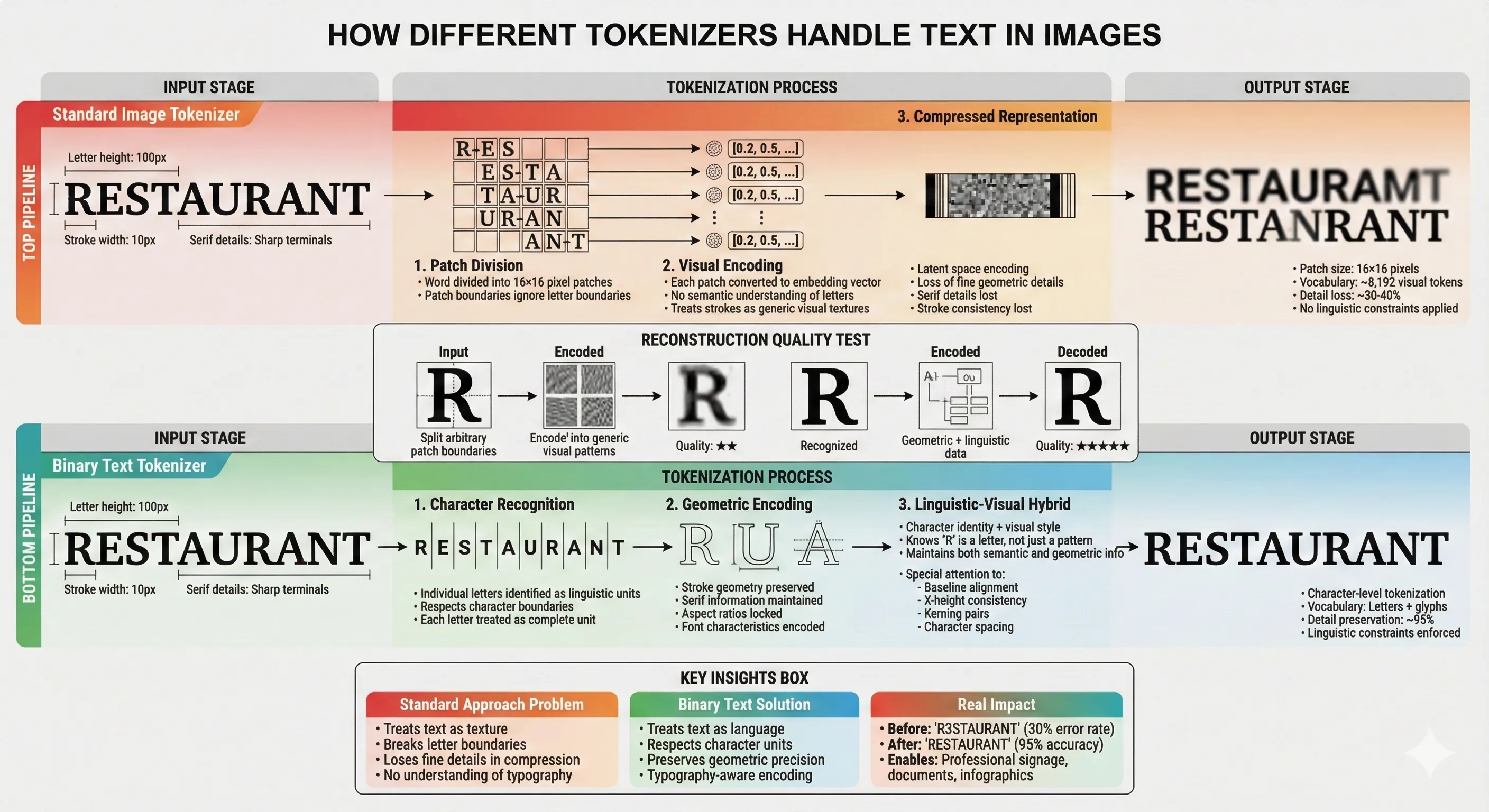
How Different Tokenizers Handle Text in Images
A binary tokenizer designed for text captures "fine-detailed features of scene text". Instead of general visual patterns, it specifically encodes the characteristics that make "B" different from "8", or "O" different from "0".
This is similar to how JPEG compression handles photos well but makes text look terrible—general-purpose compression doesn't respect the specific needs of typography. Nano Banana Pro seems to route text through a specialized processing path, giving it the precision it needs.
3. Language Model Foundation (Understanding What Text Means)
Here's where Nano Banana Pro has an unfair advantage: it's built on Gemini 3 Pro, one of the world's most advanced language models.
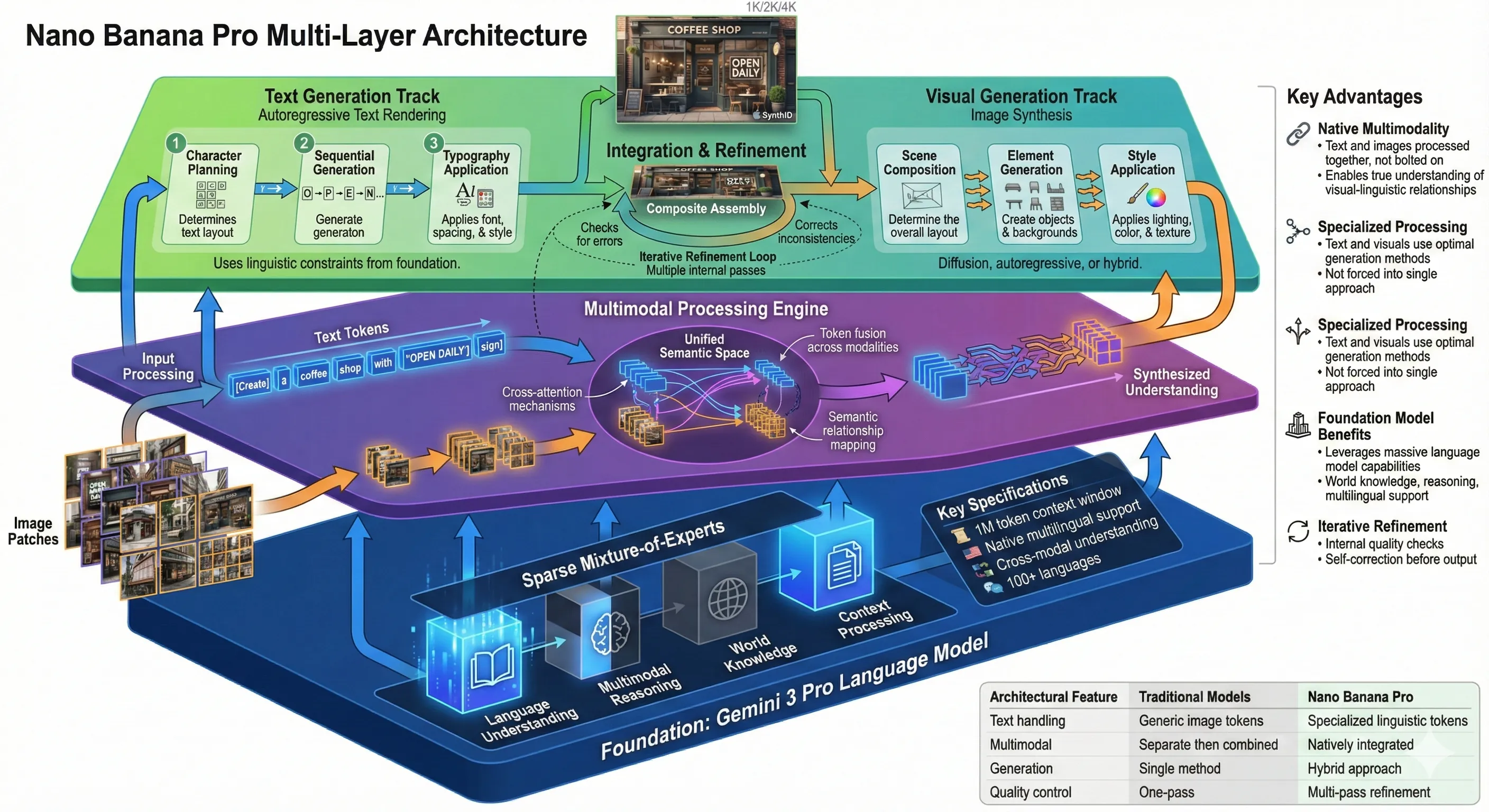
Nano Banana Pro Multi-Layer Architecture
This matters more than you might think. Other image generators learn about text indirectly—they see lots of images containing text during training and try to mimic the patterns. Nano Banana Pro actually understands language.
When you prompt it to write "Open Monday-Friday 9AM-5PM," it knows:
- Those are real words with specific spellings
- "9AM-5PM" follows a standard time format
- Monday through Friday is a sequence with semantic meaning
- This text likely appears on a business sign (contextual reasoning)
This linguistic understanding prevents the random character soup that plagued other models. The model doesn't just draw text-shaped patterns; it generates actual language, then renders it visually.
The Mixture-of-Experts Architecture
But there's another crucial piece: how Nano Banana Pro manages computational efficiency while maintaining quality.
Generating high-resolution images with precise text is computationally expensive. If you activated a massive neural network for every single pixel, image generation would take hours. Google's solution: a "sparse mixture-of-experts" (MoE) architecture.
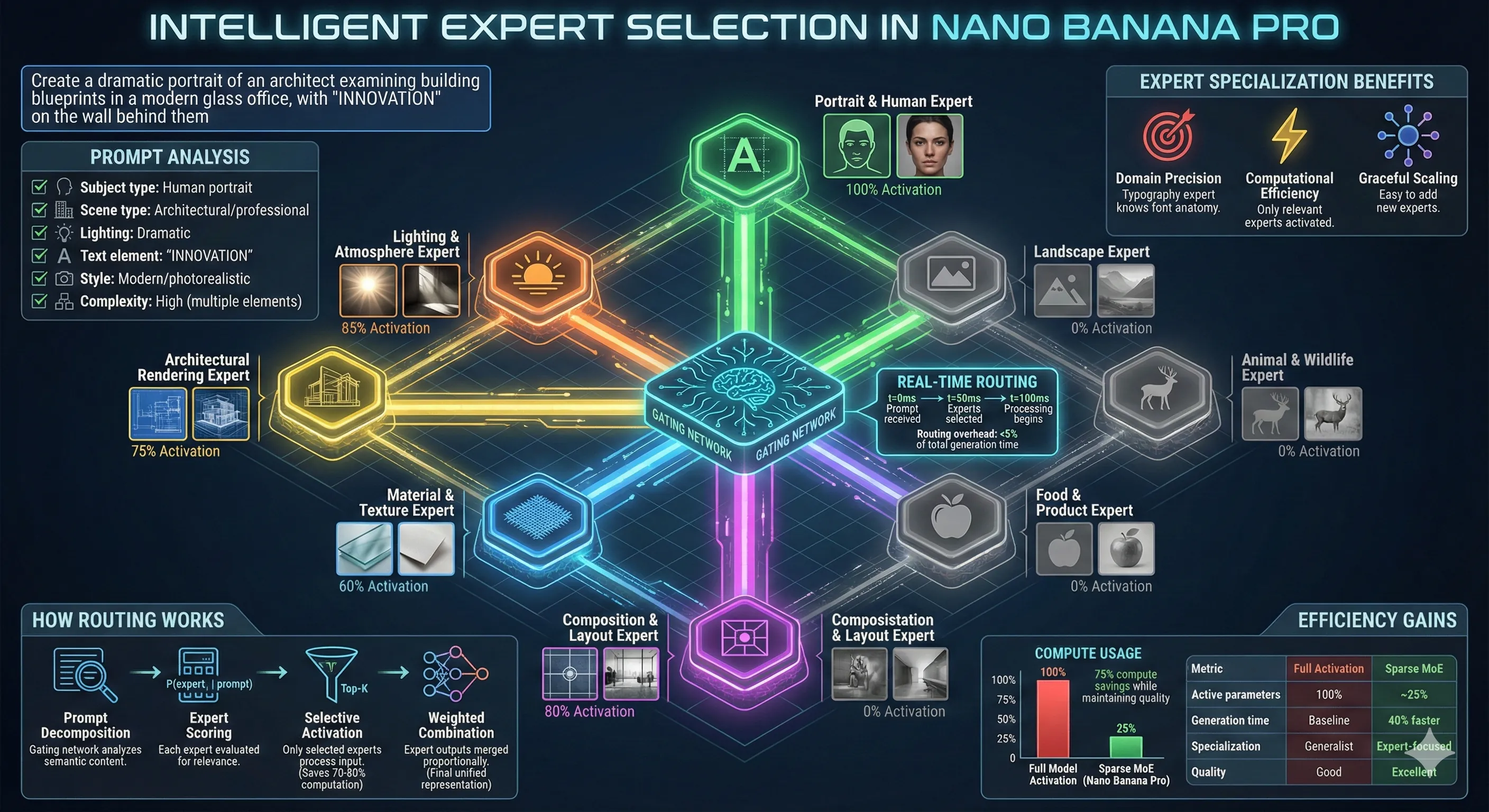
Intelligent Expert Selection in Nano Banana Pro
Think of it like a design agency where, instead of making every designer work on every project, you have specialists: one excels at typography, another at portrait photography, another at architectural rendering. For each task, you activate only the relevant specialists.11 12
In practice, this means:
- When rendering text, the model activates "experts" trained specifically on typography and text rendering
- When generating faces, it routes through experts specialized in facial features
- When creating landscapes, different experts take over
The "gating network" decides which experts to activate based on the input. This allows Nano Banana Pro to have massive total capacity (potentially hundreds of billions of parameters) while using only a fraction for any given generation task.
The benefit: specialized quality without prohibitive computational costs. The tradeoff: increased architectural complexity and harder debugging when things go wrong.
The Multi-Stage Thinking Process
One of Nano Banana Pro's most unusual features is visible in its API behavior: it generates "thought images".
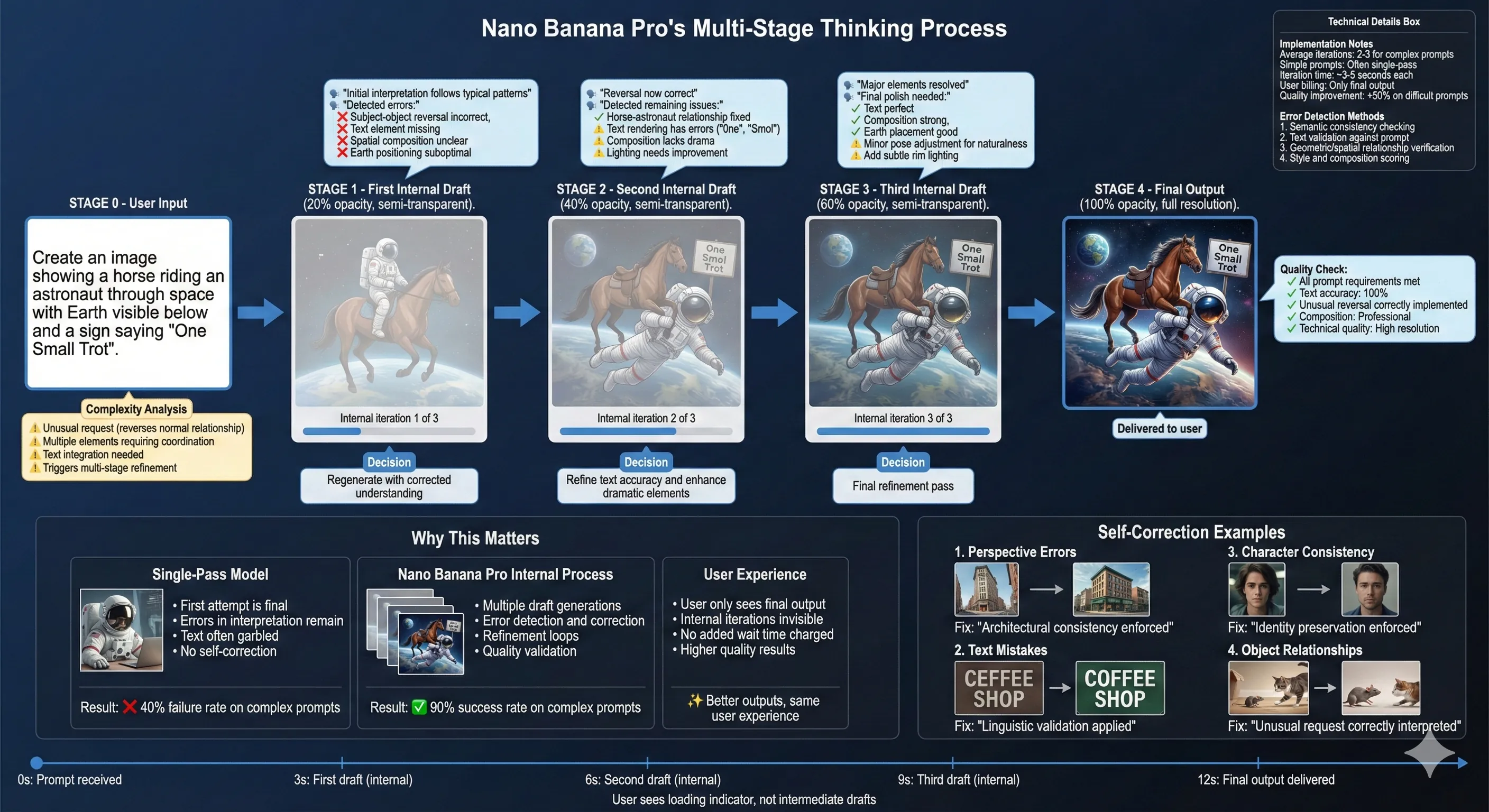
Nano Banana Pro's Multi-Stage Thinking Process
Unlike single-pass generators that give you one image and call it done, Nano Banana Pro creates intermediate drafts, evaluates them, and iteratively refines before showing you the final result. These interim images don't appear in the user interface or count toward API charges—they happen in the backend.
Why does this matter? Because complex prompts require reasoning.
If you ask for "a horse riding an astronaut" (reversing the natural order), a single-pass model might default to the more statistically common "astronaut riding a horse". Nano Banana Pro can catch this error in an early draft and correct it before final output.
Google describes this as giving the model "more time to think". It's similar to how humans sketch rough drafts before final artwork—the first attempt reveals problems that subsequent iterations can fix.
However, this multi-stage process has a cost: longer generation times. Users report waiting 15-30 seconds for complex images, compared to 5-10 seconds for simpler single-pass models.
Search Grounding: Connecting to Reality
Perhaps the most distinctive feature of Nano Banana Pro—and what genuinely separates it from competitors—is search grounding.
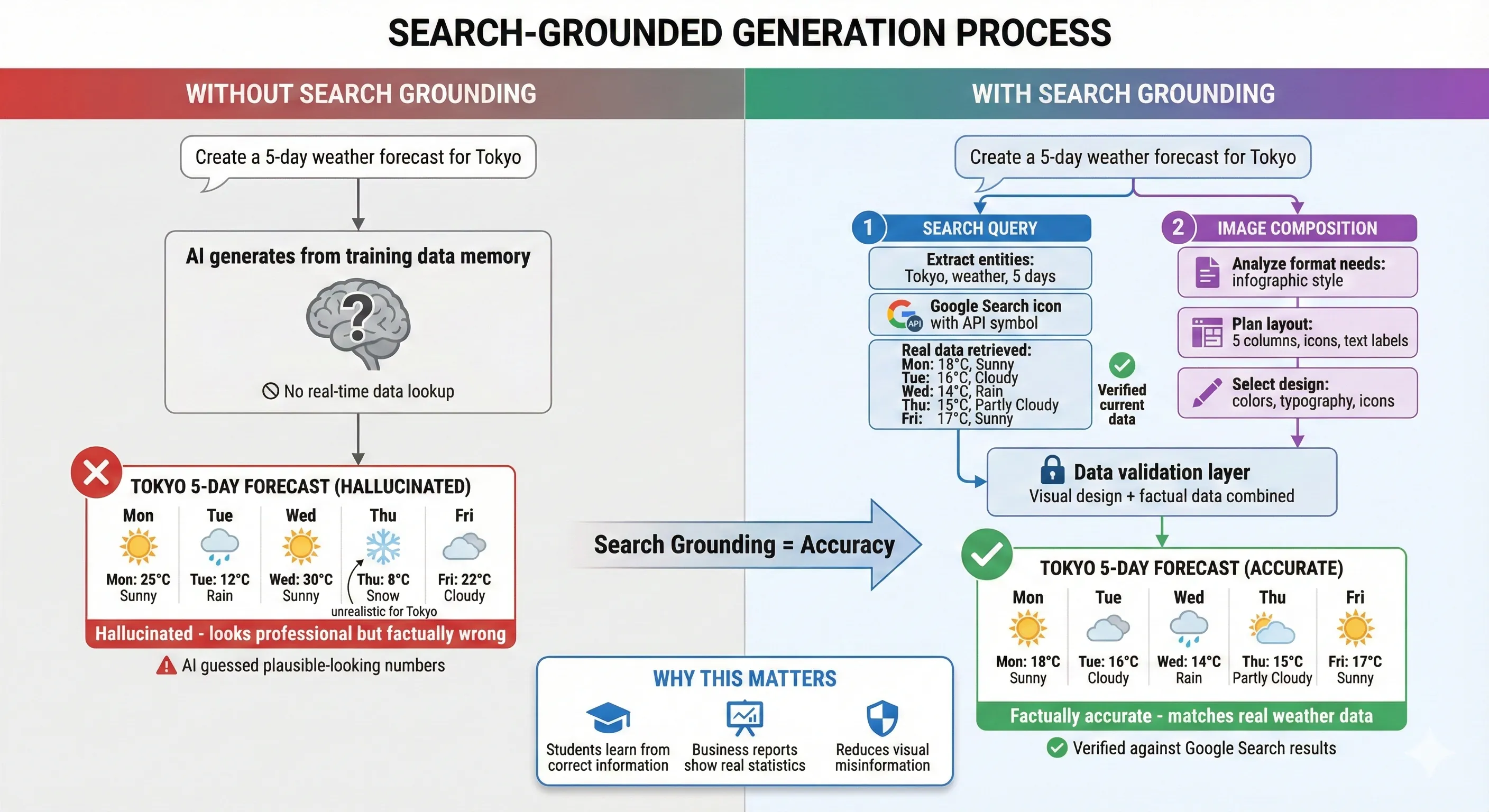
Search-Grounded Generation Process
When you prompt Nano Banana Pro to create an infographic about "current electric car sales by manufacturer," it doesn't hallucinate plausible-looking numbers. It queries Google Search for actual sales data, retrieves current figures, and generates the infographic using real information.
This works because Nano Banana Pro is multimodal from the ground up—it can:
- Understand your text prompt
- Formulate search queries to find relevant information
- Process search results (text and images)
- Synthesize that information into a visual composition
For educational content, this is transformative. A request for "diagram explaining photosynthesis" triggers research into cellular biology, retrieves scientifically accurate information, and generates a diagram that's actually correct—not just aesthetically pleasing.
The limitation? Search grounding only works when explicitly enabled and primarily supports English prompts currently. It also adds latency, since the model must wait for search results before generating.
What Makes Text Rendering Actually Work
Let's bring this back to the original question: why can Nano Banana Pro render perfect text when others can't?
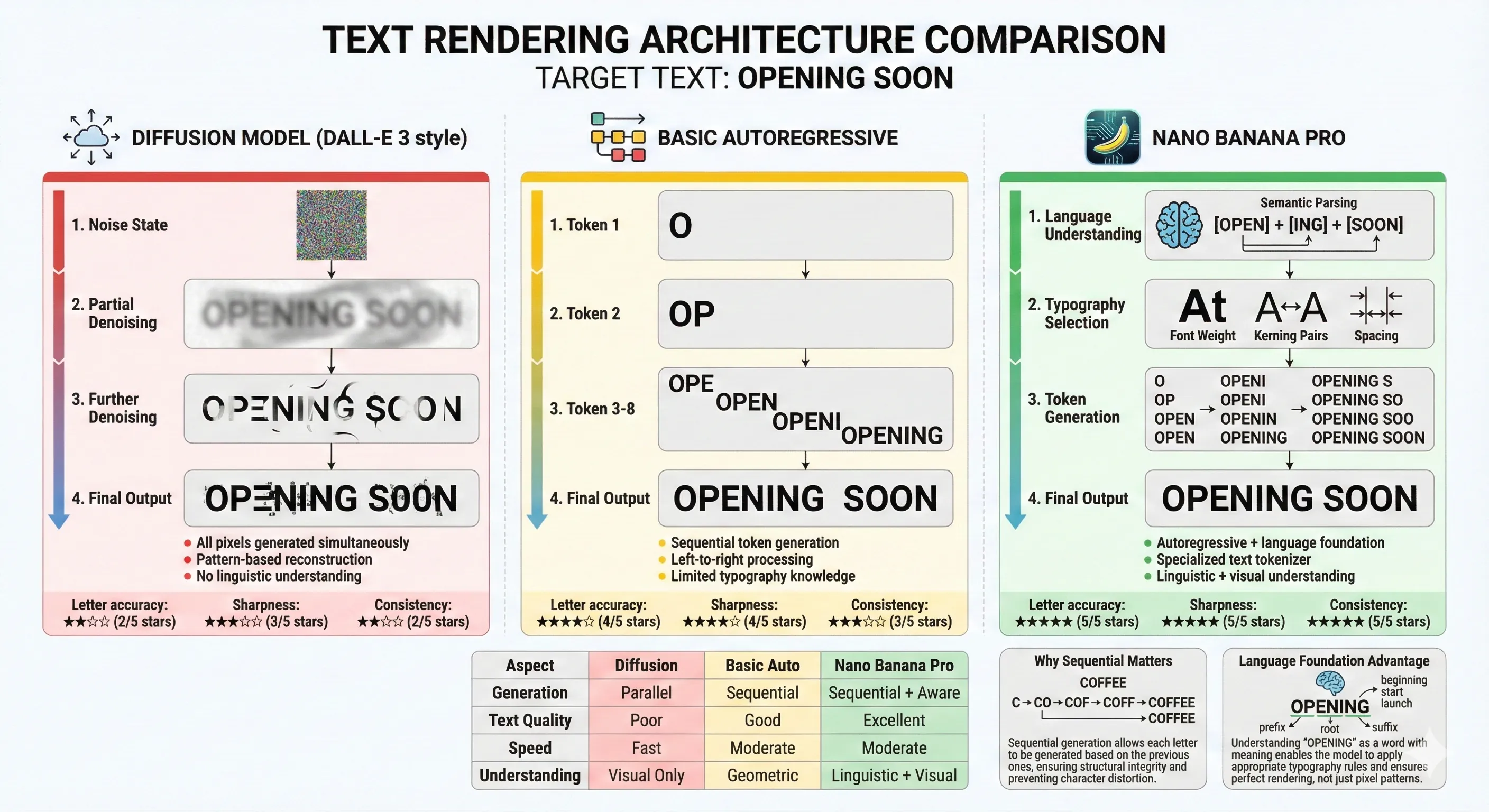
Text Rendering Architecture Comparison
The answer is convergence of multiple architectural choices:
Language Understanding Foundation: Built on Gemini 3 Pro, which actually knows how language works—spelling, grammar, semantic meaning.
Autoregressive Text Generation: Generates letters sequentially with discrete precision, rather than emerging holistically from noise.
Specialized Text Tokenization: Uses encoders optimized for preserving fine typographic details rather than general visual compression.
Multimodal Architecture: Processes text and images in the same semantic space, understanding how they relate.14
Iterative Refinement: Multi-stage generation catches and corrects errors before showing final output.
It's not magic—it's engineering. And importantly, it's not perfect.
The Limitations Nobody Advertises
For all its capabilities, Nano Banana Pro has significant limitations that become obvious in real-world use.
Reliability Problems
Reddit users report that, 80% of the time when they try to generate or change something in an image using Gemini and NanoBanana, they get no results at all. The model frequently returns "Sure, here's your image!" with no image attached, or returns the original unchanged image.15
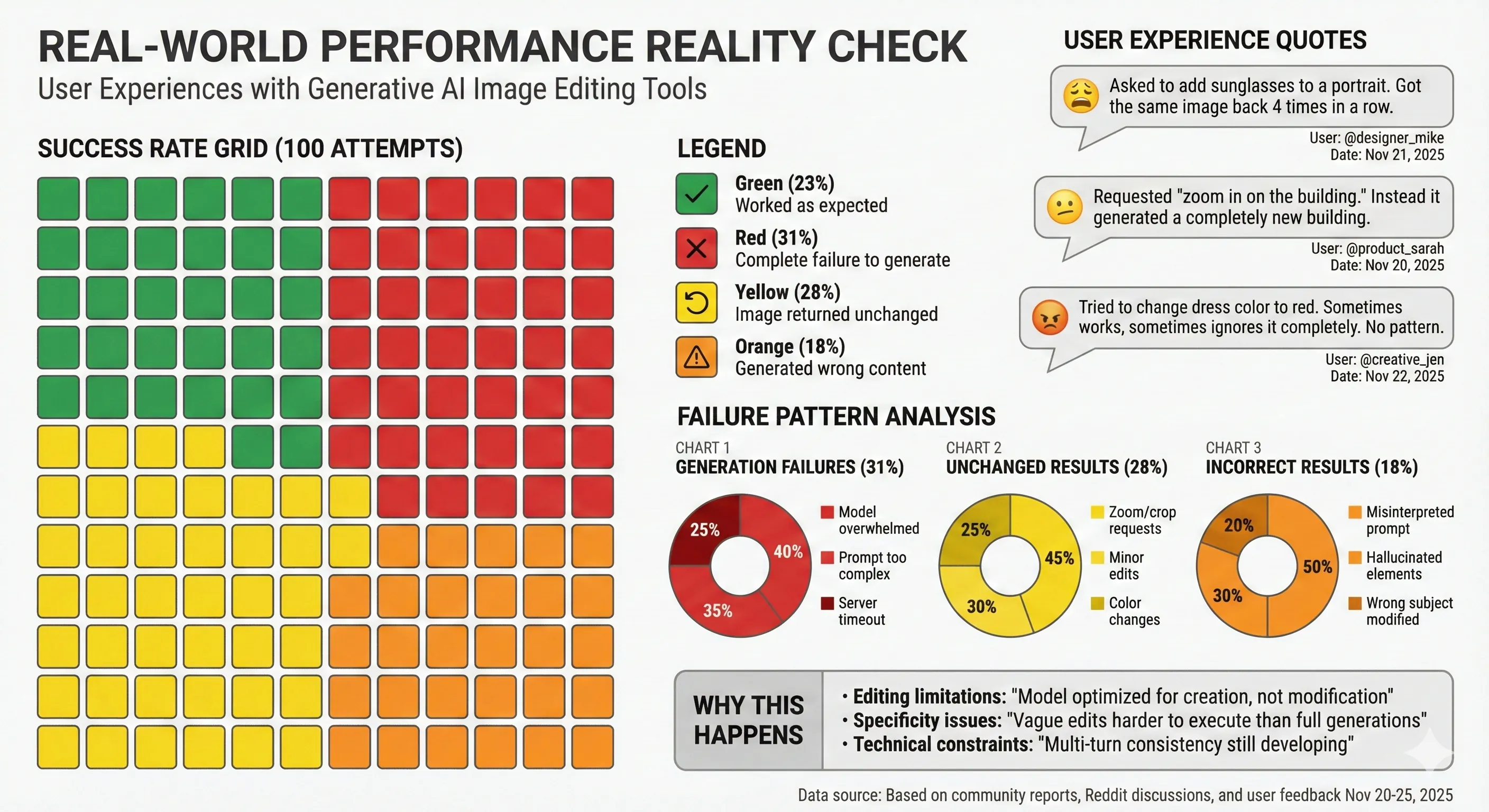
Real-World Performance Reality Check
This isn't an isolated experience. Even Google acknowledges "current limitations: the model may struggle with small faces, fine details, and perfect spelling consistency". That last point is particularly ironic given text rendering is supposed to be Nano Banana Pro's strength.
Small Detail Failures
Nano Banana (the earlier version) "struggles with fine-grained details in complex scenes". Requests to edit small objects—like changing reflection in a mirror or altering text on a product label—often return "distorted or inconsistent" outputs.
Nano Banana Pro improves on this, but the fundamental challenge remains: the model can over-edit areas you didn't intend to change unless you give extremely precise instructions.
No True Editing Capability
Despite being marketed as an image editor, Nano Banana Pro can't actually edit.
As the model itself admits in user conversations: "I cannot take an image file you upload, crop it, or mechanically zoom in on the pixels like a photo editor would".
What it does instead: generates an entirely new image that resembles your request. This means:
- Details will vary: facial expressions, clothing folds, background elements all change
- Character consistency isn't perfect: the same person may look different across iterations
- Small text must be completely redrawn and often comes out wrong
This is the fundamental difference between generative AI and traditional editing tools—one creates new images inspired by your input, the other modifies existing pixels.
Processing Time Issues
Complex images or multiple edits can result in "longer-than-expected processing times". For high-resolution images with intricate details, the AI must "analyze and modify each pixel, which naturally increases the time".
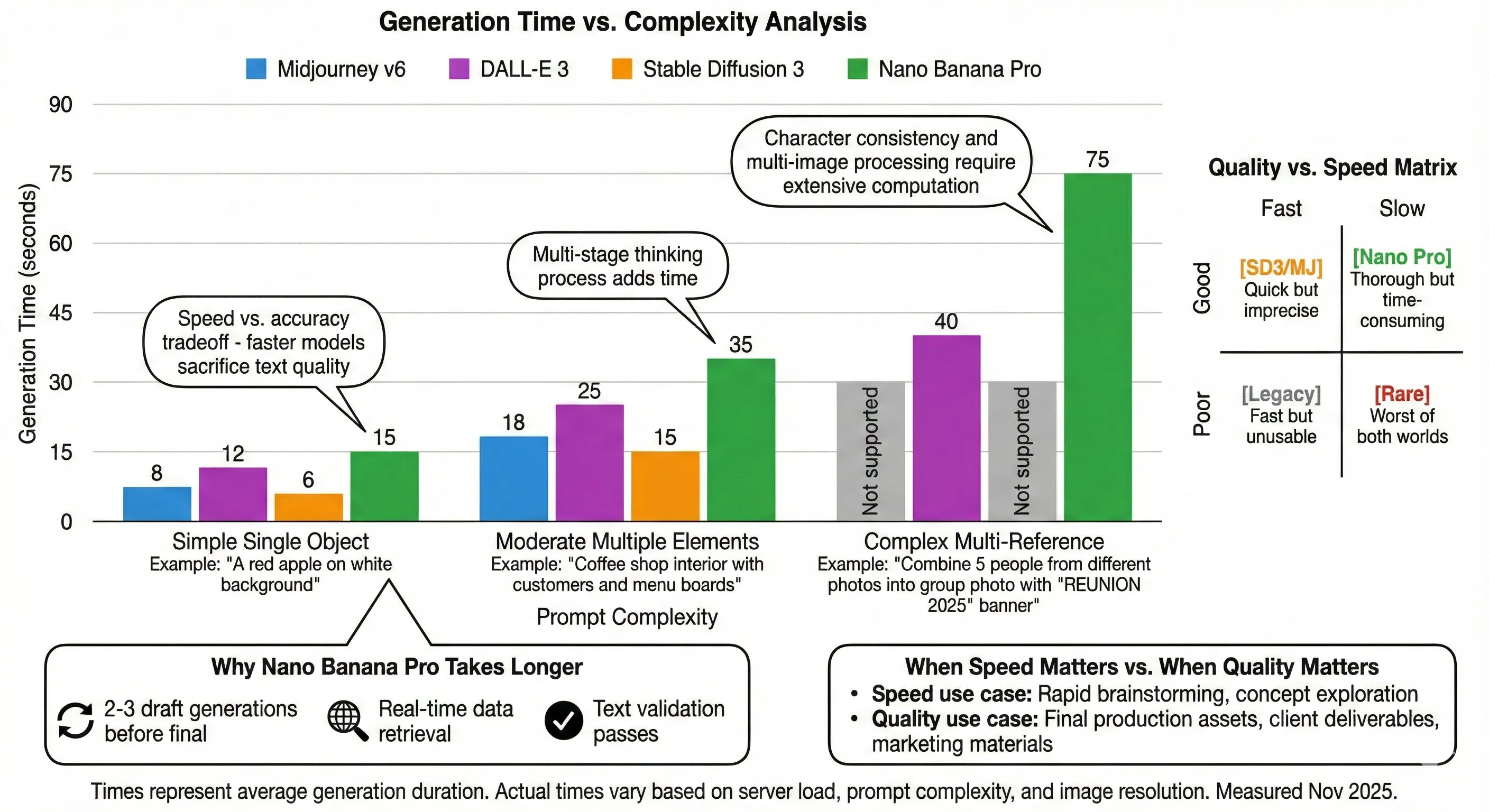
Generation Time vs. Complexity Analysis
Cloud-based processing means server traffic affects speed. During peak usage times, generations can slow to a crawl or fail entirely.
The Quality Consistency Problem
Forbes tech writer ran an experiment: asking ChatGPT, Gemini, and Grok to create simple business graphics. The conclusion: "They'll produce a distinctly AI-generated result. And it probably won't be accurate. Something will be off. It'll be entertaining, but it's unlikely to yield a usable professional result".
Even when Nano Banana Pro succeeds, outputs often require multiple regenerations to get something usable. This trial-and-error process undermines the promise of rapid, professional-quality generation.
The Architectural Tradeoffs
Every technical decision involves tradeoffs. Here's what Nano Banana Pro sacrificed to achieve its capabilities:
Speed vs. Quality: Multi-stage iterative refinement produces better results but takes longer.
Flexibility vs. Precision: Autoregressive generation gives precise text but less control over artistic style compared to diffusion models.
Specialization vs. Generalization: Mixture-of-experts architecture provides specialized capabilities but increases complexity and potential failure points.
Capability vs. Accessibility: The model's vast parameter count and computational requirements make it expensive to run, limiting free tier access and requiring cloud processing.
Comparing Approaches: Why Different Models Make Different Choices
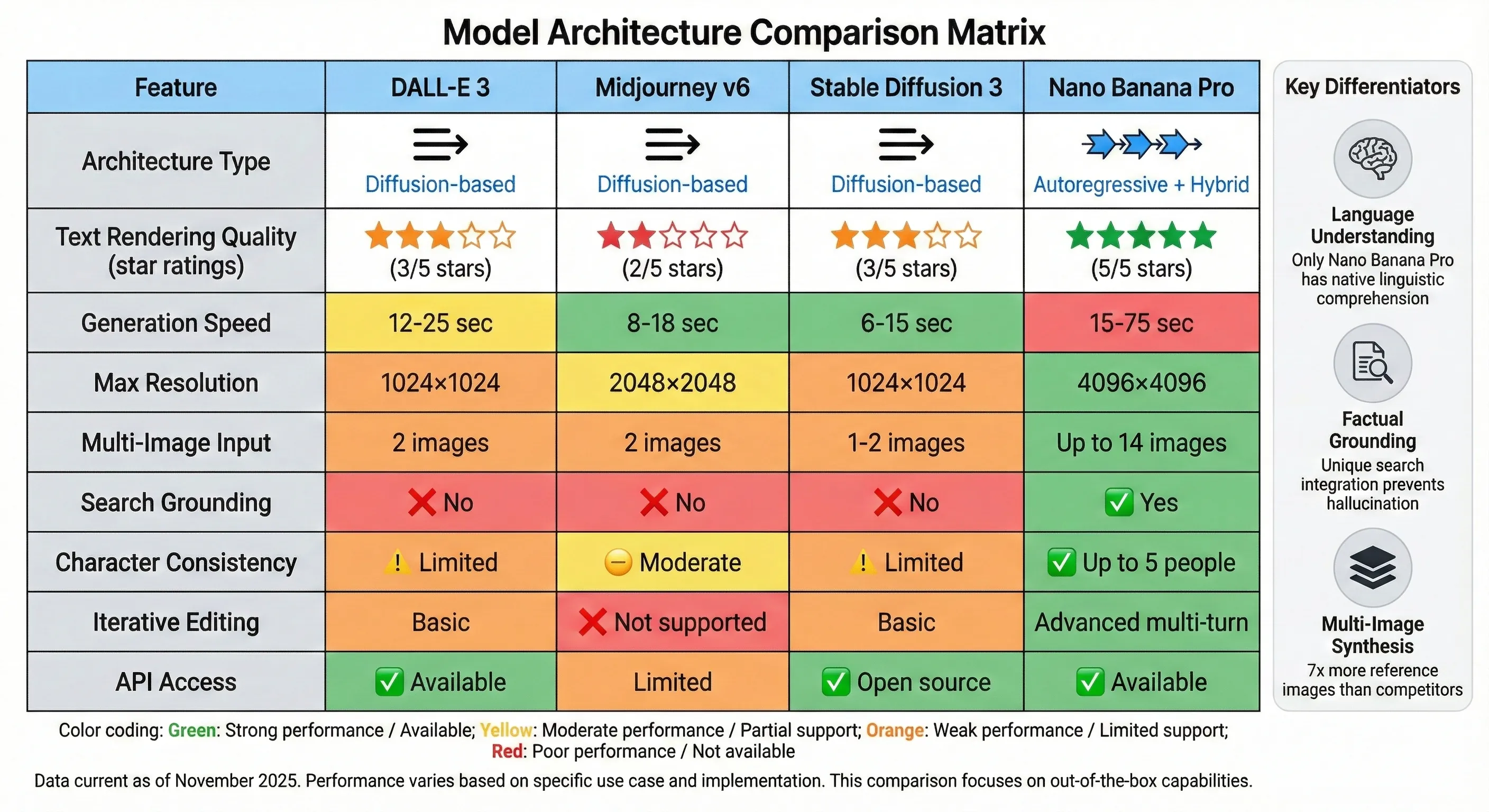
Model Architecture Comparison Matrix
The image generation space isn't converging on a single approach—different models optimize for different priorities:
Diffusion Models (DALL-E 3, Midjourney, Stable Diffusion): Prioritize artistic quality, faster generation, and aesthetic coherence. Better for creative applications where approximate text is acceptable and overall visual impact matters most.
Autoregressive Models (Nano Banana Pro, emerging research models): Prioritize precision, text accuracy, and factual grounding. Better for business applications, technical documentation, and educational content where accuracy is critical.
Hybrid Approaches: Some cutting-edge models combine both—using autoregressive generation for text and structured elements, diffusion for artistic components. This is likely where the field is heading.
Nano Banana Pro's bet: the market needs production-ready assets more than artistic experimentation tools. Time will tell if that's correct.
Real-World Applications (And Where It Falls Short)
Where It Excels
Marketing Localization: Translating advertising materials across languages while preserving design. A campaign created in English can be regenerated in Korean, Arabic, or Hindi with matching layouts.
Educational Infographics: Search-grounded generation of factually accurate diagrams. "Explain the Krebs cycle" produces a scientifically correct diagram, not artistic interpretation.
Product Mockups: Combining product photos with lifestyle scenes and marketing text. Show your product in multiple contexts without expensive photography.
Technical Documentation: Generating diagrams with accurate labels, callouts, and specifications.
Where It Struggles
Artistic Projects: Creative work prioritizing aesthetic impact over accuracy may be better served by Midjourney or Stable Diffusion.
Pixel-Perfect Requirements: Professional designers still need traditional tools for final production. Nano Banana Pro gets you 80% there, but that last 20% requires manual editing.
Consistent Character Design: While improved, maintaining perfect character consistency across multiple generations remains unreliable.
Rapid Iteration: The thinking process and search grounding add latency that slows creative workflows.
The Technical Future
Where does image generation go from here?
Video Extension: The multi-frame consistency required for video aligns well with Nano Banana Pro's architecture. Expect video generation capabilities to emerge.
Faster Iteration: Research into optimized autoregressive generation and distillation techniques will reduce processing time without sacrificing quality.
Better Consistency Models: The character consistency problem has active research attention. Future versions will likely maintain identity more reliably across generations.
Hybrid Architectures: Combining autoregressive precision for text/structure with diffusion aesthetics for artistic elements.
Extended Grounding: Beyond search, future models might ground in specific databases, design systems, or brand guidelines.
What This Means for Tech Teams
If you're a product manager, designer, or engineer evaluating AI image generation for your workflow:
For Product Managers: Nano Banana Pro enables use cases that weren't previously possible—localized marketing at scale, rapid educational content generation, data visualization with real-time information. But budget for unreliability; have fallback workflows for when it fails.
For Designers: This is a powerful sketching and ideation tool, not a replacement for design software. Use it for rapid concept generation and variation exploration, but expect to refine outputs manually.
For Engineers: The API provides programmatic access, but rate limits and processing times make it unsuitable for real-time applications. Plan for asynchronous workflows and implement retry logic.
For Everyone: Set expectations appropriately. This technology is genuinely useful, but it's not magic. The gap between "impressive demo" and "reliable production tool" remains significant.
Conclusion: Engineering Over Magic
Nano Banana Pro's ability to generate accurate text isn't a single breakthrough—it's the convergence of language model foundations, autoregressive generation, specialized tokenization, mixture-of-experts architecture, and iterative refinement.
These technical choices involve real tradeoffs: slower generation, higher computational costs, increased complexity, and new failure modes. The model is genuinely impressive and enables new use cases, but it's not revolutionary in the way ChatGPT was for text generation.
The real story isn't "AI can finally write text in images"—it's "we're beginning to understand what architectural choices enable precision in generative models". That knowledge will compound, leading to better models regardless of who builds them.
For now, Nano Banana Pro represents the state of the art in text-accurate image generation. But in a field moving this quickly, "state of the art" has a half-life measured in months, not years.
The question isn't whether this technology will get better—it will. The question is which architectural approaches will prove most durable as the field matures. Diffusion models have dominated for three years, but autoregressive approaches are mounting a serious challenge.
We're watching that competition play out in real time. And for anyone building products that need images with actual, readable text, that's a very good thing.